
A Pair of Text Analysis Explorations
After about a year of learning text analysis techniques from Text Mining with R (Silge and Robinson 2017) I had two big questions that I wanted to explore. First, the tidytext R package taught in Silge and Robinsons’s book has four different ways of measuring polarity (positivity) of text. Robinson wrote a blog post validating the performance of one method and I’ve extended his analysis to compare all four models to one another. Second, how much text do we need to provide reliable sentiment estimates?
Comparing Sentiment Lexicons
Sentiment analysis in the tidytext framework involves connecting each word in a body of text to a set of pre-determined ratings of “positive” or “negative” (sentiment lexicons). The tidytext package contains four sentiment lexicons.
In 2016, David Robinson wrote a blog post assessing the AFINN sentiment lexicon by looking at the distributions of sentiment in posts with different overall ratings from Yelp reviews. In theory, Yelp reviews with 1 star should be more negative than reviews with 2 stars and Robinson’s post demonstrates that the results of the AFINN lexicon hold true in that sense.
This section extends Robinson’s work analyze all four sentiment lexicons included in tidytext¹.
What Are the Four Lexicons?
The National Research Council of Canada (NRC) lexicon was developed by crowdsourcing sentiment ratings on Amazon’s Mechanical Turk platform². Words are rated as “positive,” “negative,” or one of eight emotions (anger, trust, etc). For this analysis, only “positive” and “negative” ratings are used and positive is converted to 1 while negative is converted to -1.
The Bing (Hu Liu 2004) lexicon was developed by searching for words adjacent to a predefined list of positive or negative terms³. The idea is that if a word consistently shows up next to “happy” that word is probably positive. Again, for this analysis, “positive” is converted to 1 while “negative” is converted to -1.
AFINN is a set of words rated on a scale from -5 to 5 with negative numbers indicating negative sentiments and positive numbers indicating positive sentiments⁴. The original scale is retained here.
Finally, the Loughran lexicon is specifically designed for analysis of positivity in shareholder reports⁵. Again, only “positive” and “negative” ratings are used here and they are converted to numeric values.
I’ve also tested a sentiment lexicon derived from the SentiWordNet project that is not included in tidytext but can be accessed through the lexicon package in R. This lexicon was developed using a similar but more complex version of the process used by Hu and Liu and is much larger⁶.
How Do They Perform?
All four sentiment lexicons, for the most part, are ordered correctly. That is to say that Yelp Reviews with fewer stars tend to have lower scores from all five lexicons. But there are some quirks in the distributions.
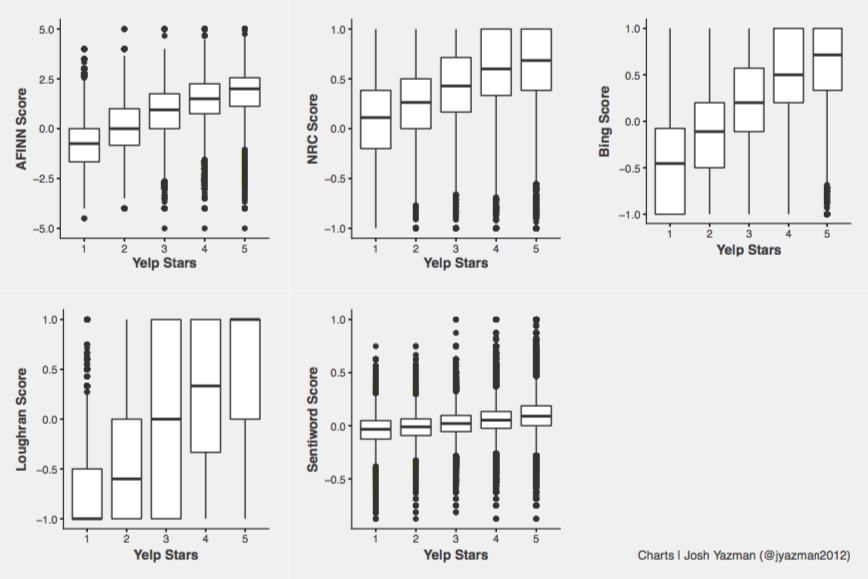
NRC errs on the side of being overly positive. The median score for 1 star reviews is a net positive! AFINN has a similar problem although it’s less egregious. Loughran orders the median distributions correctly, but the sentiment estimates are highly variable. A -1 sentiment could feasibly belong to any Yelp review between 1 and 3 stars. Sentiword scores appear to fall in the proper order, but are hard to distinguish between groups and have tons of outliers.
The Bing lexicon has fewer outliers and sentiment scores for one star ratings look reasonably separate from scores for two star ratings. Advantage — Bing.
How Much Text Do We Need For Sentiment Analysis?
One question I’ve heard repeatedly since beginning to work with text data and sentiment analysis is how much text we really need to get a solid idea of aggregate sentiments. The law of large numbers suggests that more text is better, but if we only have a little bit of text (as we would when analyzing Tweets, for example), can sentiment analysis still work?
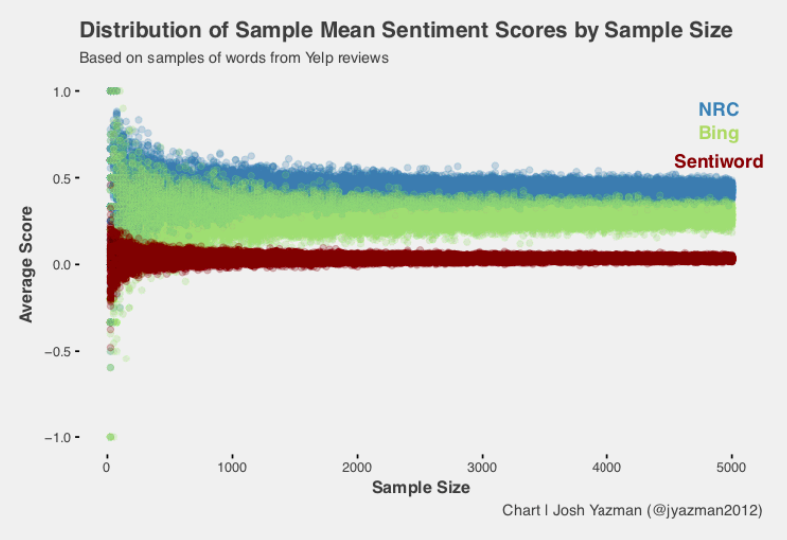
To answer this question, I went back to the Yelp dataset and repeatedly sampled text in varying amounts. As expected, the points form a funnel shape with wider distributions for lower sample sizes that converge towards the overall mean as the sample size increases. The NRC lexicon tends to be generally more positive than the Bing lexicon, but also appears to converge towards the global mean more quickly. Sentiword converges even more quickly and just generally has less variability.
Another way to look at variability is to measure the number of words required to minimize the standard deviation of sentiment estimates of different text lengths.
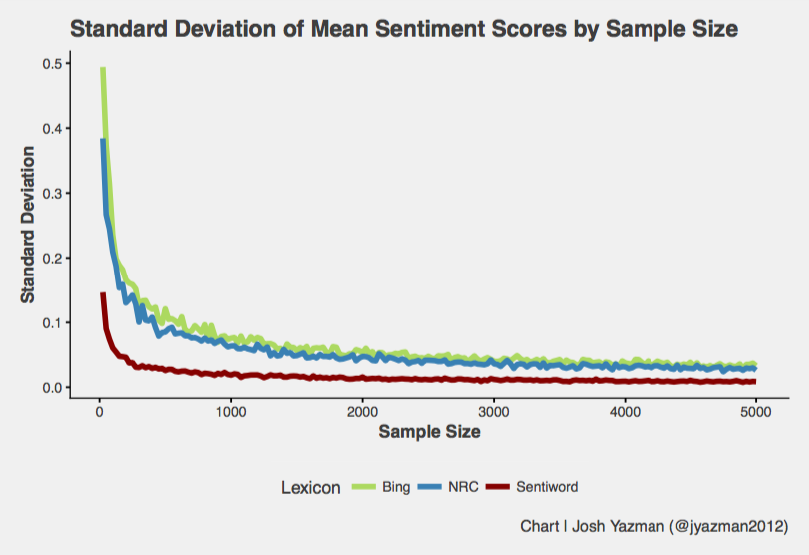
Again, the Sentiword lexicon is the optimal choice because the standard deviation starts out smaller, and approaches zero at a smaller sample size. Just a handful of words can produce a stable, if conservative, sentiment estimate from the Sentiword lexicon whereas Bing and NRC require a few hundred words and never really reach the same levels of stability.
Conclusions
The goal of this post is to answer two big questions about text analysis.
- Which sentiment lexicons provide the most accurate estimates of the positivity or negativity of a piece of text?
The Bing lexicon produces separable, accurate sentiment estimates.
- How much text is necessary to produce stable positivity estimates?
Sentiword produces very stable estimates with very little text.
When working with text that is longer than 200 or so words, I plan to use the Bing sentiment lexicon to evaluate sentiment. For smaller texts, Sentiword is the best option.
Sources
¹ Code for sentiment lexicon comparison on github ² http://saifmohammad.com/WebPages/lexicons.html ³ https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html ⁴ http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010 ⁵ http://www3.nd.edu/~mcdonald/Word_Lists.html ⁶ http://nmis.isti.cnr.it/sebastiani/Publications/LREC10.pdf